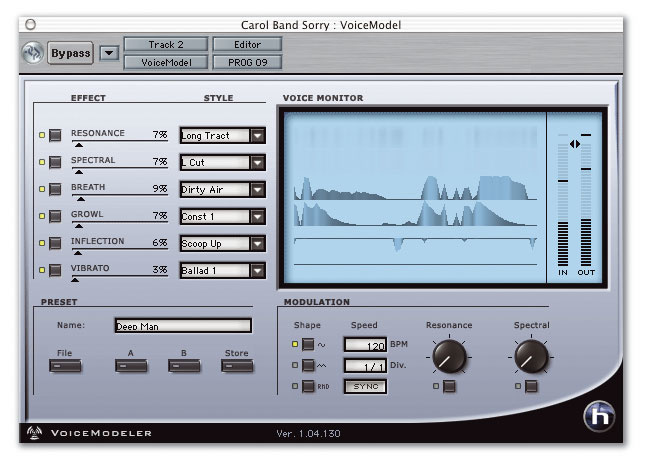
The Voice Modeler plug-in is designed to change the character of a recorded vocal, adding breathiness, chest resonance and 'growl', and allowing you to modify inflection and vibrato.
Voice Modeler is an optional plug-in for TC's Powercore platform, developed by TC-Helicon, the partnership set up between TC and Helicon to explore digital voice processing. The idea behind Voice Modeler is that an existing vocal recording can be manipulated in ways that were previously impossible, enabling the user to change fundamental aspects of the vocal character in a more or less natural way. This goes way beyond EQ or effects as Voice Modeler makes it possible to tweak the apparent size or even gender of the singer and to add growl, breath, specific vibrato styles, inflection and so on, all using a few simple sliders. The same tools may be applied to create multiple different-sounding voices from the same recording, which opens up a lot of possibilities for the creation of backing vocals or double-tracking emulation.
Voice Modeler comes with a bank of preset treatments, and behind each of its half-dozen control faders is another list of 'sub presets', each of which sets up a multitude of hidden parameters that would be beyond the scope of most users to deal with. For example, when you look behind the Resonance fader, you'll find a list of different body and gender types to choose from. Each of these body types is created by applying complex formant shifting and resonance modelling, but the user never gets involved in this.
System Requirements
- The plug-in can run only on Powercore PCI or Firewire running version 1.7 or later of the Powercore operating software.
- Windows users can run under 2000 or XP.
- Mac users need OS 10.2.3 or later. OS 9 is not supported by Voice Modeler.
- Either platform will require a reasonably brisk computer (Pentium III 500MHz or faster for Windows, or a 300MHz G3 for Apple Mac) with a minimum of 256MB RAM.
- Powercore also needs to run within a host application that can support VST or Audio Units plug-ins, and support for MOTU's Digital Performer is only possible in the Audio Units plug-In format.
- Note also that the Powercore 'no latency' mode doesn't work with this plug-in.
At The Controls
In fact, the Voice Modeler user interface is surprisingly straightforward, and occupies just one window. Styles are selected and adjusted in the Effect section, where each fader has a bypass button to the left and a drop-down menu of character styles to the right. Each of the style faders adjusts the relevant style parameter as a percentage. The usual Bypass button and patch-management buttons and menus are also provided within the window. Presets can be arranged according to user preference, and are saved as discrete files that automatically appear in the plug-in's File menu. Sub-folders can be set up to categorise the settings if desired and there's also an A/B preset comparison button for switching between two settings.
The first slider controls Resonance, which adjusts the apparent chest and vocal tract size of the singer. Some of the styles change the voice in a dynamic way that responds to the level of the voice being processed, so the results are often more complex than you might at first imagine. Here you can modify the apparent gender and size of the singer, with a Sumo wrestler at one extreme and a cartoon dinosaur at the other. Various more sensible options reside inbetween!
Spectral accesses a set of modelled equaliser response curves that are tailored to the human voice. These can be thought of as preset multi-band parametric EQ settings. By contrast, the Breath control adds breathiness to the vocal sound, but this is much more elaborate than filtered white noise — it really sounds as though it originate from a throat. It can vary from gentle breathiness to fairly hard and raspy, and again some of the options are sensitive to the dynamics of the vocal being processed.
Growl is where you turn Charlotte Church into Motorhead's Lemmy, and according to the manual, this parameter "mimics the friction activity between the larynx and epiglottis regions of the vocal tract". Again, many of the styles are sensitive to the signal dynamics, but I found that unless the effect was used very sparingly, it sounded somewhat artificial, and at high settings, it almost had me wielding my sink plunger and shouting "Exterminate! Exterminate!"
Inflection controls dynamic pitching elements of the sound, enabling the voice to be made to 'scoop' up or down to notes, and is useful both on lead vocals and on synthesized harmonies, where you may want to give each voice a slightly different pitch envelope character. Vibrato is of course another familiar pitch parameter, but the modulation shapes and onsets are modelled on actual human characteristics, not just a simple LFO synth-style vibrato. The preset names reflect the style of the vocals on which they were modelled, so you have a good idea what to expect, and the natural vibrato depth for each slide corresponds to the 50 percent fader setting.
To see what Voice Modeler is doing, there's a display window that divides the display into what TC refer to as 'lanes', where each lane monitors the activity of the associated fader's parameter. It's bit like a heart monitor in some ways, and by watching the display, you can see when the processing is most active. This is especially revealing where the character is dynamics-sensitive, as you can see exactly where pitch inflection, growl and so on are being applied.
Modulating Modelling
When I first spoke to TC-Helicon about their voice-modelling software I suggested, half jokingly, that they should include LFO modulation that would allow you to modulate a vocal's gender or some other radical parameter under LFO control. Well, it seems they've done just that, enabling the user to apply different amounts of modulation to the Resonance and Spectral parameters. This modulation can be sync'ed to MIDI, where the host application supports this, and there's also a choice of LFO wave shapes. When sync'ing to tempo, you can set the bpm and beat division. Clicking on the Div value and dragging with the mouse steps through even-numbered divisions, while a double click gets you to the odd-numbered division ratios.
When I tried this out, I found the effect to be more subtle than expected, though a lot depends on which character preset you choose to modulate. Used carefully, this feature could add more depth and movement to layered chorus parts. The modulating waveforms can be Sine, Triangle or Random (sample and hold).
Practical Applications
In addition to changing the sound of a lead or backing vocal, it's also possible to fake doubled vocals quite easily by creating a copy of the vocal part and changing its vocal character compared to the original, then using one of the inflection modes to make its pitch characteristics slightly different as well. Where multiple layered vocals are being used, each can be given a different character. There's also plenty of scope for creating non-realistic special-effect voices, from sinister, breathy serial killers to giggling cartoon characters.
I tested the plug-in using existing recordings of particularly good singers, and found that I had to be very careful in how much and what type of processing I applied. Breath is an easy one and tends to act a little like an enhancer, while vibrato is also extremely effective if you're dealing with a track that's been sung very straight. Resonance is a more radical parameter and there's often a fine line between adding enough to make a noticeable difference and adding so much that the results sounds artificial or pitch-shifted. Some of the Resonance presets are more natural-sounding that others, and providing you're not out to radically reshape the voice, you can achieve fairly natural results without too much effort.
I found Growl less easy to manage, as more than the tiniest hint sounded very artificial and slightly nasty — almost like a Dalek with a phlegmy throat! If the voice being processed is masculine and slightly rough in the first place, you can roughen it a little more without giving the game away, but trying to turn a smooth-sounding vocalist into a raunchy rocker really doesn't work for me. The Inflection parameters are interesting, and again can add a natural character to an otherwise static vocal if used sparingly. Again, excessive amounts can sound excruciatingly artificial, depending on the preset character selected, and some of the sounds I created came pretty close to yodelling!
Conclusions
Like all powerful processing tools, Voice Modeler has to be used with care if you're after a natural result, especially when you're processing a lead vocal line. It's very easy to end up with something that exhibits 'giveaway' artificial overtones or that makes the voice sound slightly distorted or lo-fi, and the Growl parameter in particular has to be applied very carefully to avoid this. You can afford to take more liberties with backing vocals, especially if they are layered, and in this application the ability to change both the sound and performance style of a voice helps create more natural-sounding multi-layered parts.
On the one hand, Voice Modeler represents ground-breaking voice modification technology, but on the other it still feels like early days in what must eventually become a major field of signal processing. One advantage of buying it as a Powercore plug-in is that it's very easy to update when improvements are released, but based on what it does now, I feel that in professional applications it would be safer in most instances to limit its use to backing vocals or to applying very subtle enhancement to lead vocal parts.
Pros
- The user interface has been made very straightforward and intuitive.
- Both subtle and outrageous vocal changes can be applied.
- Particularly good for 'faking' backing or doubled vocals.
Cons
- Lead voice processing can sound artificial unless very subtle.
Summary
Voice Modeler is an amazing piece of technology, but has to be used carefully and sparingly to achieve a natural-sounding result.
information
£179 including VAT.
TC Electronic UK +44 (0)800 917 8926.