When two sounds happen very close together, we hear them as one. This surprising phenomenon is the basis of musical pitch — and there are lots of ways to exploit it in sound design.
Films and television programmes consist of a series of individual still images, but we don't see them as such. Instead, we experience a continuous flow of visual information: a moving picture. Images that appear in rapid succession are merged in our perception because of what's called 'persistence of vision'. Any image we see persists on the retina for a short period of time — generally stated as approximately 40ms, or 1/25th of a second.
A comparable phenomenon is fundamental to human hearing, and has huge consequences for how we perceive sound and music. In this article, we'll explain how it works, and how we can exploit it through practical production tricks. The article is accompanied by a number of audio examples, which can be downloaded as a Zip archive at /sos/apr11/articles/perceptionaudio.htm. The audio examples are all numbered, so I'll refer to them simply by their number in the text.
Perceptual Integration
The ear requires time to process information, and has trouble distinguishing audio events that are very close to one another. With reference to the term used in signal processing, we'll call this phenomenon 'perceptual integration', and start by pointing out that there are two ways in which it manifests itself. In some cases, the merging of close occurrences is not complete. They're perceived as a whole, but each occurrence can still be heard if one pays close attention. In others, it becomes completely impossible to distinguish between the original occurrences, which merge to form a new and different audio object. Which of the two happens depends on how far apart the two events are.
Take two short audio samples and play them one second apart. You will hear two samples. Play them 20 or 30ms apart, and you will hear a single, compound sound: the two original samples can still be distinguished, but they appear as one entity. Play the two sounds less than 10ms apart, and you won't hear two samples any more, just a single event. We are dealing with two distinct thresholds, each one of a specific nature. The first kind of merging seems to be a psychological phenomenon: the two samples can still be discerned, but the brain spontaneously makes a single object out of them. In the second case, the problem seems to be ear‑based: there is absolutely no way we can hear two samples. The information just doesn't get through.
These two thresholds are no mere curiosities. Without them, EQs would be heard as reverberation or echoes, compression would never be transparent, and AM and FM synthesis would not exist. Worse still, we would not be able to hear pitch! In fact, it's no exaggeration to state that without perceptual integration, music would sound completely different — if, indeed, music could exist at all. In audio production, awareness of the existence of such perceptual thresholds will make you able to optimise the use of a variety of production techniques you would otherwise never have thought about in this way. The table to the right lists some situations in which perceptual integration plays an important role. .") Changing a single parameter can radically change the nature of sound(s).
Changing a single parameter can radically change the nature of sound(s).
Two Become One
Let's think in more detail about the way in which two short samples, such as impulses, are merged first into a compound sample and then into a single impulse. You can refer to audio examples 1 through 15 to hear the two transitions for yourself, and real‑world illustrations of the phenomenon are plentiful. Think about the syllable 'ta', for instance. It's really a compound object ('t” and 'a'), as can easily be confirmed if you record it and look at the waveform. But the amount of time that separates both sounds lies below the upper threshold, and we hear 't' and 'a' as a single object. Indeed, without perceptual integration, we wouldn't understand compound syllables the way we do. Nor would we be able to understand percussive sounds. Take an acoustic kick‑drum sample, for instance. The attack of such a sample is very different from its resonance: it's a high, noisy sound, whereas the resonance is a low, harmonic sound. Yet because the two sounds happen so close to each other, we hear a single compound object we identify as a 'kick drum'.
In audio production, there are lots of situations where you can take advantage of this merging. A straightforward example would be attack replacement: cut the attack from a snare drum and put it at the beginning of a cymbal sample. The two sounds will be perceptually merged, and you will get a nice hybrid. Refer to audio examples 16 to 18 to listen to the original snare, the original cymbal, and then the hybrid sample. This is but an example, and many other applications of this simple phenomenon can be imagined. A very well-made compound sound-object of this kind can be found in the Britney Spears song 'Piece Of Me': the snare sound used is a complex aggregate of many samples spread through time, and though it's easy to tell it's a compound sound, we really perceive it as a single object.
Creating Pitch
Let's try to repeat our original experiment, but this time with several impulses instead of only two. With the impulses one second apart, we hear a series of impulses — no surprise there. However, reducing the time between the impulses brings a truly spectacular change of perception: at around a 50ms spacing, we pass the upper threshold and begin to hear a granular, pitched sound. As we near 10ms and cross the lower threshold, we begin to hear a smooth, pitched waveform, and it's quite hard to remember that what you are actually hearing is a sequence of impulses. Refer to audio examples 19 to 33 in this order to witness for yourself this impressive phenomenon. Hints of pitch can also be progressively heard in examples 1 through 15, for the same reasons.
This points to a fundamental property of hearing: without perceptual time integration, we would have no sense of pitch. Notice how, in this series of examples, we begin to hear pitch when the spacing between impulses falls to around 50ms. It's no coincidence that the lowest pitch frequency humans can hear — 20Hz — corresponds to a period of 50ms.
In fact, we're often told that humans are not able to hear anything below 20Hz, but referring to our little experiment, you can see that this is misleading. Below 20Hz, we can indeed hear everything that's going on — just not as pitch. Think about it: we hear clocks ticking perfectly well, though they tick at 1Hz: we're just not able to derive pitch information from the ticking. Again, compare hearing with vision: obviously, we can see pictures below 10 frames per second, we just see them as… pictures, not as a continual stream of information in the manner of a film.
You don't need this article to be aware of the existence of pitch, so let's get a bit more practical. In audio production, reducing the interval between consecutive samples to below perceptual time thresholds can be of real interest. A good example can be found in a piece called 'Gantz Graf' by British band Autechre. In this piece, between 0'56” and 1'05”, you can witness a spectacular example of a snare‑drum loop being turned into pitch, then back into another loop. More generally, most musical sequences in this track are made from repetitions of short samples, with a repetition period always close to the time thresholds. Apparently, Autechre enjoy playing with the integration zone.
This track being admittedly a bit extreme, it's worth mentioning that the same phenomenon can also be used in more mainstream music. In modern R&B, for instance, you can easily imagine a transition between two parts of a song based on the usual removal of the kick drum and the harmonic layer, with parts of the lead vocal track being locally looped near the integration zone. This would create a hybrid vocal‑cum‑synthesizer‑like sound that could work perfectly in this kind of music.
AM Synthesis: Tremolo Becomes Timbre
The idea that simply changing the level of a sound could alter its timbre might sound odd, but this is actually a quite well‑known technique, dating back at least to the '60s. Amplitude modulation, or AM for short, was made famous by Bob Moog as a way to create sounds. It's an audio synthesis method that relies on the ear's integration time. When levels change at a rate that approaches the ear's time thresholds, they are no longer perceived as tremolo, but as adding additional harmonics which enrich the original waveform. AM synthesis converts level changes into changes in timbre.
AM synthesis converts level changes into changes in timbre.
AM synthesis uses two waveforms. The first one is called the carrier, and level changes are applied to this in a way that is governed by a second waveform. To put it another way, this second waveform modulates the carrier's level or amplitude, hence the name Amplitude Modulation. The diagram on the previous page illustrates this principle with two sine waves. When we modulate the carrier with a sine wave that has a period of one second, the timbre of the carrier appears unchanged, but we hear it fading in and out. Now let's reduce the modulation period. When it gets close to 50ms — the upper threshold of perceptual integration — the level changes are not perceived as such any more. Instead, the original waveform now exhibits a complex, granular aspect. As the lower theshold is approached, from 15ms downwards, the granular aspect disappears, and the carrier is apparently replaced by a completely different sound. Refer to audio examples 34 through 48, in this order, to hear the transition from level modulation through granular effects to timbre change.
In audio production, you can apply these principles to create interesting‑sounding samples with a real economy of means. For instance, you can use a previously recorded sample instead of a continuous carrier wave. Modulating its amplitude using an LFO that has a cycle length around the integration threshold often brings interesting results. This can be done with any number of tools: modular programming environments such as Pure Data, Max MSP and Reaktor, software synths such as Arturia's ARP 2600, and hardware analogue synths such as the Moog Voyager. If you like even simpler solutions, any DAW is capable of modulating levels using volume automation. The screen above shows basic amplitude modulation of pre‑recorded samples in Pro Tools using volume automation (and there's even a pen tool mode that draws the triangles for us).  You can use Pro Tools volume automation to process samples with amplitude modulation techniques.
You can use Pro Tools volume automation to process samples with amplitude modulation techniques.
FM Synthesis: Vibrato Becomes Timbre
FM synthesis is, to some extent, similar to AM synthesis. It also uses a base waveform called a carrier, but it is modulated in terms of frequency instead of being modulated in terms of amplitude. The diagram to the right FM synthesis converts frequency changes into changes in timbre. illustrates this principle with two sine waves. The FM technique was invented by John Chowning at Stanford University near the end of the '60s, then sold to Yamaha during the '70s, the outcome being the world‑famous DX7 synth.
FM synthesis converts frequency changes into changes in timbre. illustrates this principle with two sine waves. The FM technique was invented by John Chowning at Stanford University near the end of the '60s, then sold to Yamaha during the '70s, the outcome being the world‑famous DX7 synth.
Suppose a carrier is modulated in frequency by a waveform whose period is one second: we hear regular changes of pitch, or vibrato. Now let's reduce the modulation period. Near 50ms we begin to have trouble hearing the pitch changes and experience a strange, granular sound. Near 10ms the result loses its granularity, and a new timbre is created. Audio examples 49 to 63 in this order show the transition from frequency modulation to timbre change.
In practice, dedicated FM synths, such as the Native Instruments FM8 plug‑in, are generally not designed to function with modulation frequencies as low as this, which makes it difficult to play with the integration zone. It's often easier to use a conventional subtractive synth in which you can control pitch with an LFO — which, in practice, is most of them!
Panning, Delay & Stereo Width
A well‑known trick that takes advantage of integration time is the use of delay to create the impression of stereo width. As illustrated in the top screen overleaf An easy way to create a stereo impression., we take a mono file and put it on two distinct tracks. Pan the first track hard left and the second hard right. Then delay one of the tracks. With a one‑second delay, we can clearly hear two distinct occurrences of the same sample. If we reduce the delay to 50ms, the two occurrences are merged, and we hear only one sample spread between the left and the right speakers: the sound appears to come from both speakers simultaneously, but has a sense of 'width'. Still going downwards, this width impression remains until 20ms, after which the stereo image gets narrower and narrower. Refer to audio examples 64 to 78 to hear the transition in action.
An easy way to create a stereo impression., we take a mono file and put it on two distinct tracks. Pan the first track hard left and the second hard right. Then delay one of the tracks. With a one‑second delay, we can clearly hear two distinct occurrences of the same sample. If we reduce the delay to 50ms, the two occurrences are merged, and we hear only one sample spread between the left and the right speakers: the sound appears to come from both speakers simultaneously, but has a sense of 'width'. Still going downwards, this width impression remains until 20ms, after which the stereo image gets narrower and narrower. Refer to audio examples 64 to 78 to hear the transition in action.
This is a simple way to create stereo width, but as many producers and engineers have found, it is often better to 'double track' instrumental or vocal parts. Panning one take hard left, and the other hard right, makes the left and right channels very similar to each other, but the natural variation between the performances will mean that small details are slightly different, and, in particular, that notes won't be played at exactly the same times. Double‑tracking thus produces an effect akin to a short, random delay between the parts, making the technique a variant of the simple L/R delay, though it's more sophisticated and yields better results. Judge for yourself by listening to audio example 79. It's based on the same sample as audio examples 64 to 78, but uses two distinct guitar parts panned L/R. Compare this with audio example 69, the one that features a 50ms L/R delay.
Double‑tracking is an extremely well‑known production trick that has been used and abused in metal music. Urban and R&B music also makes extensive use of it on vocal parts, sometimes to great effect. Put your headphones on and listen to the vocal part from the song 'Bad Girl' by Danity Kane. This song is practically a showcase of vocal re‑recording and panning techniques (see http://1-1-1-1.net/IDS/?p=349 for more analysis). To return to 'Piece Of Me' by Britney Spears: not only does the snare sound take advantage of the merging effect described earlier, but it also generates a stereo width impression by using short delays between left and right channels.
Delay Becomes Comb Filtering
Take a mono file, put it on two tracks and delay one of the tracks, but this time don't pan anything to the left or right. If we set the delay at one second, we hear the same sample played twice. As we reduce the delay time to 15ms or so (the lower threshold of perceptual integration, in this case), the delay disappears and is replaced by a comb filter. This works even better using a multi‑tap delay. With a delay value set at 1s, we hear the original sample superimposed with itself over and over again, which is to be expected. At a delay value approaching 40‑50ms (theupper threshold in this case), we still can distinguish the different delay occurrences, but the overall effect is of some kind of reverb that recalls an untreated corridor. Getting nearer 10ms (the lower threshold in this case), we only hear a comb filter. Refer to audio examples 80 through 94 to listen to the transition between multi‑tap delay, weird reverb and finally comb filter.
The ear's ability to convert a multi‑tap delay into a comb filter is exploited in the GRM Comb Filter plug‑in from GRM Tools. GRM Tools seldom make harmless plug‑ins, and this one is no exception, containing a bank of five flexible comb filters that can be used as filters, delays or anything in between. If you happen to get your hands on it, try setting the 'filter time' near the integration zone: fancy results guaranteed.
Likewise, very short reverbs are not heard as reverb but as filters. Conversely, filters can be thought of in some ways as extremely short reverbs — the screen below An impulse response from a filter. shows the impulse response not of a reverb, but of a filter. This particular subject was discussed in detail in SOS September 2010 (/sos/sep10/articles/convolution.htm): see especially the section headed 'The Continuum Between Reverb And Filtering', and refer to the article's corresponding audio examples (/sos/sep10/articles/convolutionaudio.htm) 16 to 27 to hear a transition between a reverb and a filter. In the same article, I also explained how discrete echoes gradually turn into a continuous 'diffuse field' of sound when the spacing between them becomes short enough to cross the upper threshold of perceptual integration — see the section called 'Discrete Or Diffuse' and audio examples 3 to 15.
An impulse response from a filter. shows the impulse response not of a reverb, but of a filter. This particular subject was discussed in detail in SOS September 2010 (/sos/sep10/articles/convolution.htm): see especially the section headed 'The Continuum Between Reverb And Filtering', and refer to the article's corresponding audio examples (/sos/sep10/articles/convolutionaudio.htm) 16 to 27 to hear a transition between a reverb and a filter. In the same article, I also explained how discrete echoes gradually turn into a continuous 'diffuse field' of sound when the spacing between them becomes short enough to cross the upper threshold of perceptual integration — see the section called 'Discrete Or Diffuse' and audio examples 3 to 15.
Dynamics & Distortion
Dynamic compression involves levelling signal amplitude: any part of the signal that goes over a given level threshold will be attenuated. Consider a signal that's fed into a compressor. Suddenly, a peak appears that's above the level threshold: compression kicks in, and negative gain is applied. However, the gain can't be applied instantaneously. If it was, the signal would simply be clipped, generating harmonic distortion. This can be interesting in certain cases, but the basic purpose of compression remains compression, not distortion. As a consequence, gain‑reduction has to be applied gradually. The amount of reduction should be 0dB at the moment the signal goes over the threshold, and then reach its full value after a small amount of time; the Attack time setting on a compressor determines exactly how much time.
The screen to the right Attack time is an important parameter of dynamic compression. shows the results of feeding a square wave through a compressor using a variety of attack times. In this screenshot, the attenuation applied by the compressor (the Digidesign Dynamics III plug‑in) is clearly visible. When attack time is set at 300ms, the action of the gain reduction can clearly be heard as a gradual change in level. When we reduce the attack time to 10ms (the lower time threshold in this case), it's not possible to hear this as level change any more. Instead, we perceive the envelope change almost as a transient — an 'attack' that now introduces the sound. Refer to audio examples 95 to 103 to hear this effect. For comparison purposes, audio example 104 contains the original square wave without progressive attenuation.
Attack time is an important parameter of dynamic compression. shows the results of feeding a square wave through a compressor using a variety of attack times. In this screenshot, the attenuation applied by the compressor (the Digidesign Dynamics III plug‑in) is clearly visible. When attack time is set at 300ms, the action of the gain reduction can clearly be heard as a gradual change in level. When we reduce the attack time to 10ms (the lower time threshold in this case), it's not possible to hear this as level change any more. Instead, we perceive the envelope change almost as a transient — an 'attack' that now introduces the sound. Refer to audio examples 95 to 103 to hear this effect. For comparison purposes, audio example 104 contains the original square wave without progressive attenuation.
Of course, there is much more to dynamic compression than the attack time: other factors, such as the shape of the attack envelope, the release time, and the release envelope shape, all have the potential to affect our perception of the source sound. In music production, compressors are often set up with time constants that fall below the threshold of perceptual integration, and this is one reason why we think of compressors as having a 'sound' of their own, rather than simply turning the level of the source material up or down.
A Starting Point
This article covers many situations in which perceptual time integration can bring unexpected and spectacular results from basic modifications of the audio signal. Think about it: since when are simple level changes supposed to add harmonics to a sample? Yet it's the principle at the base of AM synthesis. And how on earth can a simple delay actually be a comb filter? Yet it takes only a few seconds in any DAW to build a comb filter without any plug‑ins. There are many other examples that this article doesn't cover. For instance, what happens if you automate the centre frequency of a shelf EQ to make it move very quickly? Or automate panning of a mono track so it switches rapidly from left to right? Try these and more experiments for yourself, and you might discover effects you never thought could exist.
Why Perceptual Integration Exists
Perceptual integration is an interesting phenomenon and one that's very important for music production. But why does it exist? As I explained in the main text, the upper threshold of perceptual integration lies between 30 and 60 milliseconds, depending on the situation. This seems to be a cognitive phenomenon that is based in the brain, and is not fully understood. On the other hand, the lower threshold, which lies between 10 and 20 ms, depending on the circumstances, originates in the physics of the ear, and is easier to understand.
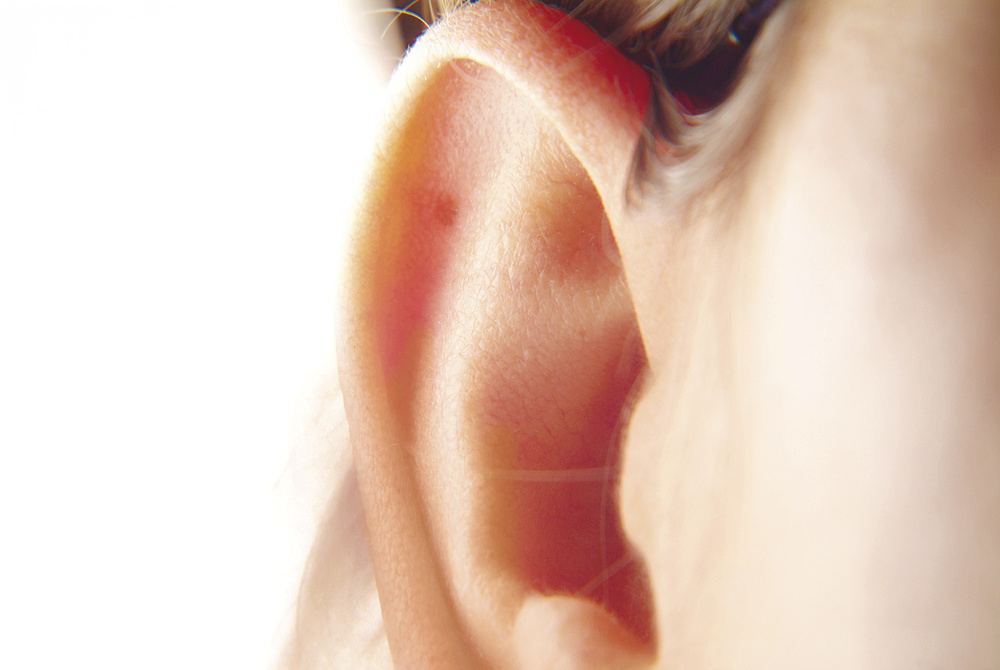
The key idea here is inertia. Put a heavy book on a table, and try to move it very quickly from one point to another: no matter what you do, the book will resist the acceleration you apply to it. With regard to the movement you want it to make, the book acts like a transducer — like a reverb or an EQ, in fact, except that it's mechanical instead of being electrical or digital. The input of the 'book transducer' is the movement you try to apply to it, and its output is the movement it actually makes. Now, as we saw in March's SOS (/sos/mar11/articles/how-the-ear-works.htm) our ears are also mechanical transducers, which means that they also display inertia. There is a difference between the signal that goes into the ear, and the signal that reaches the cilia cells.
The illustration to the right  Mechanical inertia of the ear prevents us from distinguishing samples that are too close to each other.schematically shows the difference between those two signals, when the input is a short impulse. Because it is made from mechanical parts, the ear resists the movement the impulse is trying to force it to make: this explains the slowly increasing aspect of the response's first part. Then, without stimulus, the ear parts fall back to their original position. Naturally, if the two input impulses are very close to each other, the 'ear transducer' doesn't have time to complete its response to the first impulse before the second one arrives. As a consequence, the two impulses are merged. This exactly corresponds to what is described at the beginning of this article, when we were merging two sound objects into a single one: as far as we can tell, the two impulses are joined into a single one.
Mechanical inertia of the ear prevents us from distinguishing samples that are too close to each other.schematically shows the difference between those two signals, when the input is a short impulse. Because it is made from mechanical parts, the ear resists the movement the impulse is trying to force it to make: this explains the slowly increasing aspect of the response's first part. Then, without stimulus, the ear parts fall back to their original position. Naturally, if the two input impulses are very close to each other, the 'ear transducer' doesn't have time to complete its response to the first impulse before the second one arrives. As a consequence, the two impulses are merged. This exactly corresponds to what is described at the beginning of this article, when we were merging two sound objects into a single one: as far as we can tell, the two impulses are joined into a single one.
(Readers with a scientific background who specialise in psychoacoustics may be wondering what my proof is for the claim that the upper and lower time thresholds I keep referring to originate respectively from the brain and the ear. To the best of my abilities, I think this is a safe and reasonable assertion, but I can't prove it. Still, in a comparable field, it has been proven that persistence of vision is eye‑centred, whereas perception of movement is brain‑centred. I'm eager to see similar research concerning hearing.)