Sold through and marketed by United Plugins, and supporting all the usual Mac/Windows formats, including AU, VST3 and AAX, Voxessor provides a user‑friendly toolkit for improving the sound of spoken voice. It’s intended to appeal to anyone doing podcasts or voiceovers but, as with most outwardly simple plug‑ins designed by this company, what goes on under the hood is based at least in part on a spectral algorithm.
We’re informed that although it’s been optimised for the spoken word, Voxessor can also be used on conventional sung vocal tracks, and that it may well appeal to some rap artists too. The process also includes dynamic EQ and a proprietary de‑essing algorithm, as well as a more conventional compressor, a gate and an automatic EQ matching system that works by analysing a few words of your own voice.
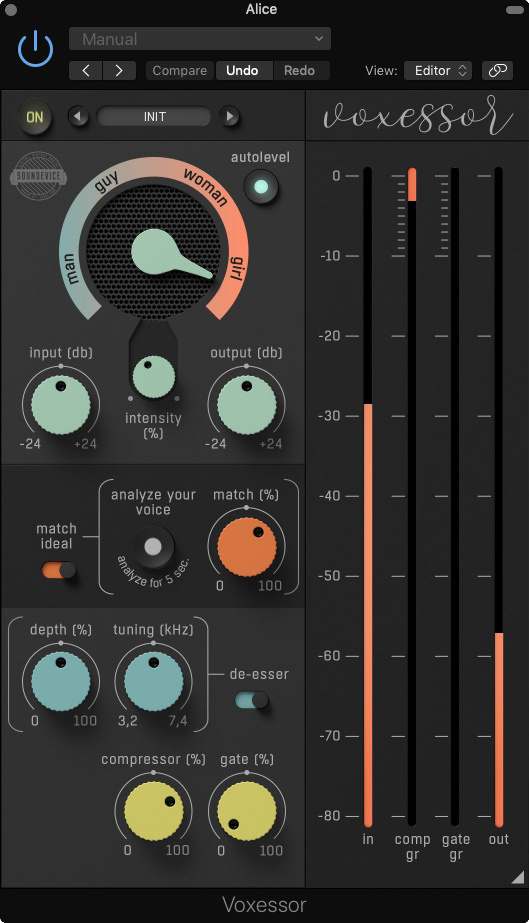
The large Mode pointer control at the top of the window covers the range for both male and female voices, and this determines what part of the spectrum will be emphasised — this has to be set by ear. It is as easy to dial in as EQ though, even if exactly what goes on behind the scenes is not divulged. Designer Boris Carloff explained that the processing references archetypes of good‑sounding spoken voices at different timbres, presumably to help massage the input in the right direction. An Intensity control, which essentially sets the wet/dry mix, adjusts the amount of processing, so at this stage only the Mode and Intensity controls need to be adjusted. There are level controls for the input and output, and a large metering section is located to the right of the window. An Autolevel button provides a more constant volume.
For a more personalised solution, you can turn to the analysis section, which is directly below. Once you have pressed the button and recorded your voice sample, the orange Match knob determines how much processing will be applied. Again, this isn’t a straightforward match EQ but instead works at a spectral level, referencing those ‘ideal’ voices. What it adds is also related to the setting of the Mode dial. We’re on more familiar ground with the lower sections, as the de‑esser has just two controls: one for frequency, one for the amount of attenuation. The compressor and gate are even simpler, with just one knob apiece.
...although it’s been optimised for the spoken word, Voxessor can also be used on conventional sung vocal tracks, and that it may well appeal to some rap artists too.
It’s difficult to quantify exactly what is going on inside Voxessor, but the end result appears to be a balancing of the chest frequencies, adding more weight and richness where needed, plus a massaging of the mids and highs to provide a sense of presence and intelligibility. While similar results may be obtainable using combinations of other plug‑ins, you’d probably spend a lot more time finding the ideal settings, and for anybody making podcasts using budget mics, the speed and ease of use could be a big improvement.
Match mode provided a good fix for my own voice, and the only thing you really need to be wary of is adding too much processing — you do still need to listen, and let your ears decide what is enough. The de‑esser works well, especially for something with two‑knob simplicity, while the no‑frills one‑knob compressor adds a welcome bit of weight and consistency.
Best of all is that if you aren’t sure whether or not the plug‑in will work magic on your own voice, you can download a demo and try it for yourself.